PC GAMESS SCF Benchmark.
According to Pople [1]
and Schlegel [2] the cost of direct SCF scales with molecular
size as N2.7, and conventional SCF as N3.5. Therefore, they advise
to use only Direct SCF. Gaussian98W uses the Direct algorithm by default. However the
GAMESS Manual [9] states: "the direct approach always
requires more CPU time". However, Granovsky [10] says
"If it's possible to perform the desired calculations using conventional (not direct)
methods - use them". Which statement is true?
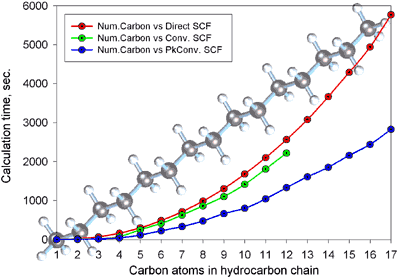
My numerical experiment [3] with the PC GAMESS [4,5,6,7] shows that the cost of SCF for the Direct and Conventional
methods is N2.3 and N2.3, respectively, i.e. they are equal
(see the diagram to the right). Why is the second scale smaller than Pople asserted? It is
mainly due to the use of a new technology in PC GAMESS – packing of AO integrals [8] (of course the idea isn't new, but PC GAMESS uses a
better algorithm than other programs, e.g. Gaussian or GAMESS). Therefore, the
bottleneck in SCF is “widened” at least twice. |
 |
After looking at these results my
colleague Alex Khalizov told me that they were wrong
because of different number of overlapping integrals in selected series of hydrocarbons.
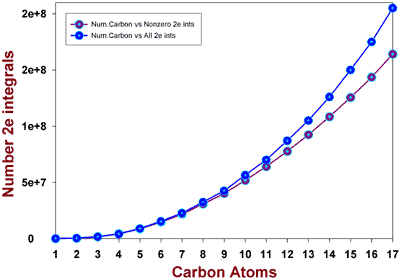
And as a result of Schwarz inequality test,
(zero 2-e ints)/(nonzero 2-e ints) ratio is different for different terms of the series. I
have plotted the relation between the number of two-electron integrals (all and nonzero,
correspondingly) versus the number of carbon atoms in hydrocarbon chain. These
dependencies appear to be nonlinear.
The fitting equation for nonzero integrals is:
Nint = 2.969E5 * Ncarb2.234.
For all integrals this equation is
Nint = 1.887E5 * Ncarb2.466.
Exponent of power in the first expression is close to my estimate of the SCF cost time. |
 |
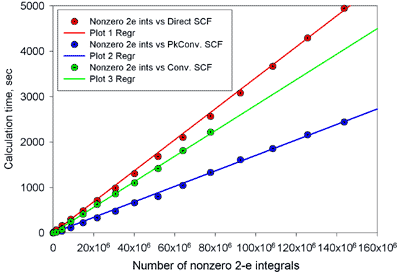
| Consider now the relation between the number
of nonzero two-electron integrals and SCF calculation times (to the right). As expected, this dependence is linear, but the line slopes are distinctly
different. For the Direct SCF line the tangent is 3.38e-5, for the Conventional SCF it is
2.84e-5 and for the Packed Conventional SCF it is 1.70e-5. Thus, it is apparent that with
the increasing number of integrals the Packed Conventional SCF calculation time grows
slower than Conventional and Direct SCF time. Q.E.D. |
 |
Therefore, if you use PC GAMESS you can forget about the
Direct SCF!
(of course if you have not too small disk)
References
[1] Gaussian 98W Manual.
[2] H. B. Schlegel and M. J. Frisch,
"Computational Bottlenecks in Molecular Orbital Calculations," in Theoretical
and Computational Models for Organic Chemistry, Ed. J. S. Formosinho, I. G. Csizmadia and
L. G. Arnaut (Kluwer Academic, The Netherlands, 1991) 5.
[3] Configuration of my
computer is Celeron 333 MHz, 64 Mb RAM, 4.2 Gb HDD; 36 MFlop/sec.
[4] GAMESS
Home Page
[5] PC GAMESS Home Page
[6] PC GAMESS Home Page Mirror
[7] Alex. A. Granovsky, Moscow State University.
[8] http://classic.chem.msu.su/gran/gamess/packing.html
[9] GAMESS Manual, Section 4 - Further
Information (REFS.DOC)
[10] http://classic.chem.msu.su/gran/gamess/hints.html
P.S. If you would like to test my result on your
own computer, input files are here. I would greatly appreciate
if you could send me the results of your tests. I will summarize and post them. Also I
welcome any questions and comments
P.P.S. If you have found any errors (syntactical,
grammatical, notional or other), please e-mail me.
After appearing of my letter in CCL
conference many people have visiting my page (approximatelly 200 in three days). Some of
they have write to my. Below I have summarize all replies.
Received: Tue, 9 Feb 1999 21:10:30 +0500
From: Matt Challacombe [email protected]
Dear Andrew,
Nice web page! I'd like to point out that it is now possible to perform SCF calculations
that scale entirely as N, rather than N^2.x If you are interested, please see my web page
for papers (new ones should be up soon).
All the best, Matt
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
+ Matt Challacombe, Ph.D. http://www.t12.lanl.gov/~mchalla/
+
+ Los Alamos National Laboratory email: [email protected] +
+ Theoretical Division vmail: (505) 698-4112 +
+ Group T-12, Mail Stop B268 phone: (505) 665-5905 +
+ Los Alamos, New Mexico 87545 fax: (505) 665-3909 +
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
To my regret I can't get to the Matt's page.
However I guess that scale smaller that N^2.x simply can be reached by storing integrals
in memory. But this real only for very small molecules and basis sets.
Received: Wed, 10 Feb 1999 12:47:00 +0500
From: "Slawomir Janicki" [email protected]
Dear Andrew
As you requested I am sending you my corrections to your page. You did a great job!
Thanks for your effort.
Slawomir Janicki
[email protected]
Many thanks, Slawomir!
Received: Wed, 10 Feb 1999 21:36:15 +0500
From: John McKelvey [email protected]
I can only wonder how the conclusions you made woyuld differ as a function of CPU
speed. I would think that Direct SCF would be improved significantly for a faster chip.
What speed was the CPU you used in your tests?
Thanks!
John
Configuration of my computer is Celeron 333 MHz,
64 Mb RAM, 4.2 Gb HDD; 36 MFlop/sec.
Certainly, I would like to compare my result with other ones obtained at other platforms
and processors. However, I have not access to many computers. Therefore, I have asked for
tests of other systems on my page. If they would be are accessible, I could to do more
complete analysis of SCF timing. I guess that speed of conventional SCF calculation is
strongly depended from CPU/DISK ratio unlike direct SCF. If one have fast disk subsystem
then conventional SCF is best choice. However, if one have power CPU but slow disk then
direct SCF is more preferably.
Received: Wed, 10 Feb 1999 21:37:09 +0500
From: "Alex. A. Granovsky" [email protected]
Dear Andrew,
I've already visited your pages. I only want to note the following point.
With the AO current implementation of AO integrals packing, there exists the theoretical
limit for the degree of compression. Namely, 12 or 20 bytes (needed by GAMESS to store
both the integral value and its four indices) will be packed to 4.5 bytes in the
best case. Actually, instead of 4.5 bytes per integral we have in average
approximately 5-5.5 bytes/integral.
Thus, the speed up should be asymptotically linear as compared with non packed case.
Yours,
Alex. Granovsky
Very useful note. But I don't know packing method
and don't say more.
Received: Sat, 13 Feb 1999 06:36:19 +0500
From: "Windus, Theresa L" [email protected]
Dear Andrew,
You have done a very nice job of looking at the different methods in GAMESS.
However, there is one point that you have missed in your analysis. The integral
computations in GAMESS are slower than the integral computations in Gaussian.
Because Gaussian computes integrals faster, disk I/O CAN be a bottleneck for the
calculation (especially when there are not many high angular momentum basis
functions in the basis set) and therefore make the scaling of the conventional method look
worse. It wasn't clear to me what basis set you used, but if it is mostly s and p
functions, I think you would find a different scaling in Gaussian where the direct
method should scale better.
Hope this is makes sense.
Sincerely,
Theresa Windus
At last, I have been explained why GAMESS have
scale different from Pople and Schlegel estimations.
Many thanks!
About used basis set. It is 6-31G*, i.e. s,p and d functions.
However, why GAMESS is slower in integral computations than Gaussian? I worked with
Gaussian, and it was slower than GAMESS on my tests. I am going to do some numerical
experiments with Gaussian and compare it with GAMESS. I hope that I will do it soon. May
be, it will make clear situation.
Received: Tue, 16 Feb 1999 23:08:31 +0500
From: "Windus, Theresa L" [email protected]
Dear Andrew,
GAMESS uses a relatively old code using Rys polynomials to calculate the
integrals. Gaussian uses newer and faster recursion relationships to calculate
the integrals. It has been a while since I have checked this, but at one point
the fast integrals in Gaussian were only used for direct calculations and their
"old" integral code was used for conventional disk based methods. This,
therefore, can also skew the scaling that you see in Gaussian alone. Again, I
don't know if this is the current case.
Theresa
It is pity that GAMESS has old code for integral computations.
I want to belive that GAMESS will incorporate advanced method for integral evaluation.
Thanks for explanation.